Map Views Dependency in SQL Server Database
While working on an ETL framework, we had the need to know, which views are dependent on which table, regardless of the depth.
Each object in the data mart had a view that joins and maps the data from the EDW layer in the data mart table. Our ETL framework would create a record every time new data was added, deleted or updated in the EDW layer, and we wanted to use that information to know which tables in the data mart needs to be updated due to a change in one or more depending objects in EDW.
The query to list the dependency hierarchy is utilizing the recursive CTE feature of SQL Server.
with
dependencies as
/*this recursive CTE will list all the tables in the database,
and then list all the views that depended on the table, no matter how deep the dependency go (as long as it via views).
*/
(
select dep.referenced_entity_name, OBJECT_NAME(dep.referencing_id) AS referencing_entity_name,
OBJECT_SCHEMA_NAME(dep.referenced_id) + '.' + OBJECT_NAME(dep.referenced_id) as source,
object_schema_name(referencing_id) + '.' + object_name(referencing_id) as dependent,
referencing_id as dependent_object_id,
1 as depth,
cast(OBJECT_SCHEMA_NAME(dep.referenced_id) + '.' + OBJECT_NAME(dep.referenced_id) + ' -> ' + object_schema_name(referencing_id) + '.' + object_name(referencing_id) as varchar(400)) as path,
so.type_desc AS source_type,
do.type_desc AS dependent_type
from sys.sql_expression_dependencies as dep
inner join sys.objects as so
on so.object_id = dep.referenced_id
inner join sys.objects as do
on do.object_id = dep.referencing_id
where dep.referenced_id <> dep.referencing_id
and so.type = 'U'
AND do.type = 'V'
union all
select dep2.referenced_entity_name, OBJECT_NAME(dep.referencing_id) AS referencing_entity_name,
dep2.source,
object_schema_name(referencing_id) + '.' + object_name(referencing_id) as dependent,
dep.referencing_id as dependent_object_id,
dep2.depth + 1 as depth,
cast(dep2.path + ' -> ' + object_schema_name(referencing_id) + '.' + object_name(referencing_id) as varchar(400)) as path,
dep2.source_type,
dep2.dependent_type
from sys.sql_expression_dependencies as dep
inner join dependencies as dep2
ON dep.referenced_entity_name = dep2.referencing_entity_name
and dep2.source <> object_schema_name(referencing_id) + '.' + object_name(referencing_id)
)
select d.source ,
d.dependent ,
d.dependent_object_id ,
d.depth ,
d.path ,
d.source_type,
d.dependent_type
from dependencies as d
The result for this query against the AdventureWorksDW will show this:
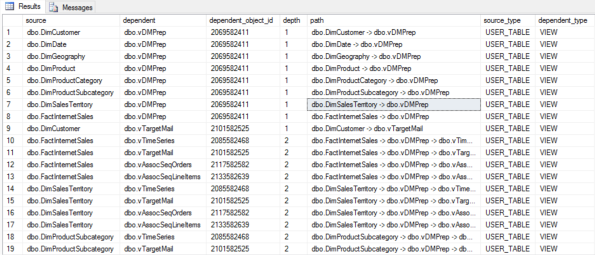
The source column lists the name of the database object (table or view) that the view depends on. The dependent column lists the name of the dependent view. The dependent_object_id is the object id of the view. The depth tells us what is the distance between the dependent view and the source object. 1 means that the dependent view is accesing the source object directly, while 2 means that the view is using a nother view, that is then dependent on the source item. Since the query is recursive, it can show depths of 3, 4 and more, however it is most likely not to be the case for most database implementations. The path column list the path from source to dependent view.
You can modify this SQL to also show more then views, or show dependency between views, to do that you will need to adjust the object types constraint in the first where clause.
Loading SAS files with SSIS
Hi
I’ve been given an assignment to load data from a SAS Institute data file to SQL Server using SSIS. How hard can that be I thought to my self. All I needed to do was to find the oledb provider for SAS, install it on my machine, and use it within SSIS, a no brainer!
Well first it took some time for me to actually find the oledb provider. You see SAS Institute provide it for free, which is great, but they kinda keep it in a secret place. If you google “sas oledb provider” the first result is this, which is a general documation spot for the SAS Oledb Provider, which is a great source for content regarding how to use the provider, but where to download it? Well you need to click on some links, only to get to a page that tells you where you can download it, but guess what, the part that tells you where to download it from is NOT a link, it’s URL indeed, but it’s not marked as a link, and very hard to find in all the other text on the page. Unfortunately I’m not a reader, I’m a scanner (we’ll get back to that later also). When I need to read something fast, which is almost always, I scan the text looking for known patterns instead of actually reading the entire content. So when I look for a link for downloading the file, I tend to not read any irrelevant text, which in this case was the link, disguising as normal text. But I’m a good person, so I’ll help you guys with that, here is the direct link to the download page, if you need to download it. You’ll need to register and confirm by an email first.
Now that I got the provider, I opened SSIS and did the following:
- Created anew connection manager to my SAS file using the “Native OLE DB\SAS Local Data Provider 9.3”
- In the Server or FileName I wrote the full path of the file name (which we’ll later go back to)
- Pressing Test Connection to make sure it works and pressed OK
- Added a new OLE DB Source to my data flow task
- In the OLE DB Source Editor I tried to pick the table in the SAS file, only to get an error message with the following content: “fn =ydedopn; context =sasej9lib.dll.”
So I thought I’ll google that, and guess what, one result only, to a linked in post of a guy asking for help with the same problem, no one with a solution.
I thought well let’s try and isolate the issue, so I started windows console project, to test to connectivity logic using an OleDb provider to the SAS file. I’ve spent 2 hours on this, trying with all kind of different ways to make it work, but either I got an empty data table, or the same error message as in SSIS. Frustrated I kept on going back and forward between the SAS website documentation, looking for a hint, and there, just before I was to give up, I saw the problem!
In the documentation it states that the datasource property is “A physical directory that contains the SAS data set that you want to access with the connection.” How did I missed that? (damn you scanners!) I shouldn’t have used the file name, but the file directory! The provider treats the folder as the “database” and each file is a “table” in the “database”!
Changing that simple fact, I was able to select a table from the Ole Db Source Editor, and beside some page code warnings which I’ll look into later, everything works as is should.
So the conclusions are:
- don’t scan the documentation, read it! (this conclusion is pointed to me only)
- when pointing to a SAS Institute files use only the directory in the data source!
I hope this will help others
/Rafi
Catch Custom Events with SSIS Event Handler
Background
When I started working for PensionDanmark summer 2011, we started looking into using SSIS as the main ETL tool for the Datawarehouse team. One of the main requirements were to be able to bring SSIS into the enterprise scale, and to be able to design and implement a pattern that will be able to cover a wide range of ETL related tasks though out the enterprise.
I knew that SSIS is lacking some of these enterprise needs, and when I saw Andy Leonard approach using a framework, I decided to try and implement one similar in PensionDanmark. What really got my attention was the ability to have a meta data driven approach to the execution of SSIS, and the ability to centralize the settings of logging, and by that to allow multiple child package to be simple and yet to inherit a complex set of events logging, that can be maintained easily, without effecting the child packages.
After the implementation of the first version of the framework, we had a request from the users to be able to report on non standard events. I thought that it should be quite simple, as SSIS has a custom event, and SSIS Script Task Component has the ability to fire custom events. But I was wrong to think it was that simple, because the SSIS event handler has no implementation for the custom event.
The problem description is like this: the frameworks central logging feature is build on the fact that the event handlers of the parent package (the framework package) is able to catch events that are fired in the child package too. But there is no event handler for the custom event, so what can we do?
A Solution
What we need is a workaround, that will allow us to catch a custom event, fired in the child package, using an event handler of the parent package. I started to look into the types of events which have an event handler, and to see weather I could hijack one, and make it act as a custom event handler, and than I saw it, the perfect victim for the task, the VariableChanged event handler!
Why is it perfect?
- I’ve never used it in production in my years developing SSIS packages.
- The event is fully controlled by the developer. That is the SSIS developer chooses to enable this event on a variable. This is something we cannot do with any other event!
- I believe that it’s by far a event that one is willing to live without for the price of having custom event in a centralize manner. I know I would :-).
Let’s take a look on how we actually doing it:
Here is the parent package, it’s made simple, in order to better illustrate the event catch scenario. An SSIS Framework looks of course more complex than this simple parent package.

The parent package has a script component in the OnVariableValueChanged. With that script we will need to catch the variables which are available for this type of event, and use them to log the real event that is fired by the child package.

This is how the script looks like:
'The follwing variables are accesable from this type of event handler: 'System::TaskName 'System::SourceName 'System::VariableDescription 'System::VariableID 'System::VariableName 'System::VariableValue Public Sub Main() Dim S As String 'Building a string that proof that the values of the variables ' is originated from the event fires in the child package S = "VariableName: " & Dts.Variables("System::VariableName") _ .Value.ToString() & vbCrLf _ & "VariableID: " & Dts.Variables("System::VariableID") _ .Value.ToString() & vbCrLf _ & "VariableDescription: " & Dts.Variables("System::VariableDescription") _ .Value.ToString() & vbCrLf _ & "VariableValue: " & Dts.Variables("System::VariableValue") _ .Value.ToString() & vbCrLf _ & "TaskName: " & Dts.Variables("System::TaskName") _ .Value.ToString() & vbCrLf _ & "SourceName: " & Dts.Variables("System::SourceName") _ .Value.ToString() 'Showing the string value as a message box MsgBox(S) Dts.TaskResult = ScriptResults.Success End Sub
Note I’m not telling you here how to log the event, but just showing which variables are available for usage, and how to manipulate this variables from the event fire method
Here is a screen shot of the child package:

The first script task is there just to proof the fact that the event is not fired, unless we set the event on a variable.
The second script task is where the magic is done, let’s look into the code:
Public Sub Main() Dts.Events().FireCustomEvent("OnVariableValueChanged", _ "", _ New Object(3) _ { _ "First Value", _ "Second Value", _ "Third Value", _ "Forth Value"}, _ "", _ False) Dts.TaskResult = ScriptResults.Success End Sub
What we are doing here is this, we fire a custom event, of type OnVariableValueChanged. The FireCustomEvent can take an object, as the third parameter, and this object is later used by the SSIS Event Handler. I’ve doing some testing, and found out that at least 4 items can be included in this object, and that this 4 objects correspond to 4 SSIS system variables, which are accessible in the SSIS Event Handler. All 4 are strings, so we must use strings, to prevent errors.
To illustrate that, I’m sending 4 text values, let’s look into what happens when we ran the parent package:

Let’s zoom in:

In real life, we will use this 4 strings to send information about the custom event, it’s source, level, severity what ever is relevant for the specific system requirements.
The entire project is available for download.
New Localizations for Azure DateStream
When I saw that Boyan Penev (blog) together with the SQL Azure Team had put a date dimension feed for free on the DataMarket, I thought wouldn’t it be great if we all contribute to the content of this valuable free data feeds?
I come from Israel, and I live in Denmark. So I thought that I’ll be able to contribute with a translation of the calendar to danish and Hebrew. I contacted Boyan, and sent him the translated versions.
I was happy to read this morning that the translated feeds are now available, for free, on the DataMarket. 4 new languages were added (Hebrew, Danish, German and Bulgarian), and other languages are on the way.
I hope you’ll find this information useful.
Using Filtered Index to Maintain Unique Key Combinations
When building a datawarehouse project, the usage of many to many tables is done to support multiple natural keys which are mapped to the same surrogate key. This is happening often with products and EAN codes. Each version of the same product will get a different EAN code, cause that make sense for the inventory guys who work in the warehouse, but for analysis from the marketing department’s point of view, the product is the same, and sometimes we want to just add the sales of all versions of the same products to measure how many liters of “Orange Juice” were sold in a given month, regardless of the package variant (normal size bottle vs promotion 10% more bottle).
Another issue with EAN code is that EAN codes are suppose to be unique world wide, but it’s OK and common practice to reuse EAN codes which have been out of the market for 3 months. Because EAN codes cost money, companies reuse old EAN codes.
You can read about how to solve these issues using map tables at Thomas Kejser’s Database Blog
(part 1 – part 2)
What I want to show you is how you can maintain the uniqueness of your mapping table using filtered indexes.
So let’s describe the problem first:
We have a table Product and a table ProductEAN, which represents the many to many relations that may occur between a products and EAN codes. The ProductEAN table includes some columns which specify the date span ,for which the EAN mapping is relevant, this is done to support reload of historic data in the right context, this is also marked using a boolean columns IsActive. There is also a boolean indicator for which EAN is the default EAN, that is the EAN we wish to use in the a report.

Now the thing is that we wish to make sure that invalid data is not entered to the ProductEAN table. Invalid data can be if the same EAN is mapped to 2 different ProductKey, and both of them are an active mapping. Another case of invalid data is if more than one EAN is marked to be the default for the same ProductKey.
We can implement this data consistency checks using filtered indexes. Now it’s not why Microsoft chose to implement them, never the less it gets the job done!
create unique index UIX_ProductEAN_Only_One_Active_Product_Per_EAN on ProductEAN (EAN) where IsActive = 1; create unique index UIX_ProductEAN_Only_One_Default_EAN_Per_Product on ProductEAN (Productkey) where IsDefault = 1;
So what is it we are doing here?
A unique index will not allow duplicates to occur. So when we build an unique index on the EAN column, we force that the same EAN code will not be entered twice to the table. Note that this alone is not enough in order to solve the problem, because we do allow the same EAN to exist multiple times, but we allow only one active relation for each EAN, so by adding the where clause to the index definition, we are telling the database engine to build the unique index only on the columns which have the IsActive value = 1, hence we are forcing uniqueness only on a sub set of the table, which apply to the condition in the where clause .
Lets look into some data:
select * from ProductEAN where EAN = '5019487040114'

Any attempt to invalidate the business rule will result in a invalidation of the index, and the query will fail.
update ProductEAN set IsActive = 1 where ProductEANKey = 8
This will result in the following error message:
Msg 2601, Level 14, State 1, Line 1
Cannot insert duplicate key row in object ‘dbo.ProductEAN’ with unique index ‘UIX_ProductEAN_Only_One_Active_Product_Per_EAN’.
The duplicate key value is (5019487040114).
The statement has been terminated.
To summarize, we are able to enforce uniqueness on a sub set of a table, using a unique filtered index. This allows us to maintain the business rule of single active relation, and/or single default relation for each member in the many to many relation.
Remember to name the indexes wisely, so that the error message becomes self describing.
